让我们使用 C99 和 C++11 完成常见的数据科学任务。

虽然 Python 和 R 之类的语言在数据科学中越来越受欢迎,但是 C 和 C++ 对于高效的数据科学来说是一个不错的选择。在本文中,我们将使用 C99 和 C++11 编写一个程序,该程序使用 Anscombe 的四重奏数据集,下面将对其进行解释。
我在一篇涉及 Python 和 GNU Octave 的文章中写了我不断学习编程语言的动机,值得大家回顾。这里所有的程序都需要在命令行上运行,而不是在图形用户界面(GUI)上运行。完整的示例可在 polyglot_fit 存储库中找到。
编程任务
你将在本系列中编写的程序:
- 从 CSV 文件中读取数据
- 用直线插值数据(即
f(x)=m ⋅ x + q) - 将结果绘制到图像文件
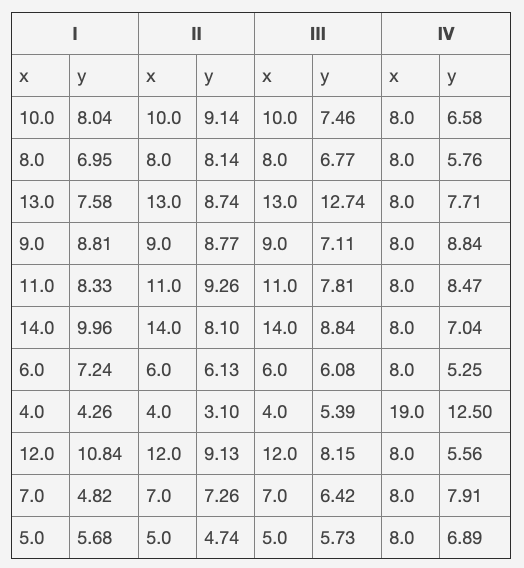
这是许多数据科学家遇到的普遍情况。示例数据是 Anscombe 的四重奏的第一组,如下表所示。这是一组人工构建的数据,当拟合直线时可以提供相同的结果,但是它们的曲线非常不同。数据文件是一个文本文件,其中的制表符用作列分隔符,前几行作为标题。该任务将仅使用第一组(即前两列)。
C 语言的方式
C 语言是通用编程语言,是当今使用最广泛的语言之一(依据 TIOBE 指数、RedMonk 编程语言排名、编程语言流行度指数和 GitHub Octoverse 状态 得来)。这是一种相当古老的语言(大约诞生在 1973 年),并且用它编写了许多成功的程序(例如 Linux 内核和 Git 仅是其中的两个例子)。它也是最接近计算机内部运行机制的语言之一,因为它直接用于操作内存。它是一种编译语言;因此,源代码必须由编译器转换为机器代码。它的标准库很小,功能也不多,因此人们开发了其它库来提供缺少的功能。
我最常在数字运算中使用该语言,主要是因为其性能。我觉得使用起来很繁琐,因为它需要很多样板代码,但是它在各种环境中都得到了很好的支持。C99 标准是最新版本,增加了一些漂亮的功能,并且得到了编译器的良好支持。
我将一路介绍 C 和 C++ 编程的必要背景,以便初学者和高级用户都可以继续学习。
安装
要使用 C99 进行开发,你需要一个编译器。我通常使用 Clang,不过 GCC 是另一个有效的开源编译器。对于线性拟合,我选择使用 GNU 科学库。对于绘图,我找不到任何明智的库,因此该程序依赖于外部程序:Gnuplot。该示例还使用动态数据结构来存储数据,该结构在伯克利软件分发版(BSD)中定义。
在 Fedora 中安装很容易:
sudo dnf install clang gnuplot gsl gsl-devel
代码注释
在 C99 中,注释的格式是在行的开头放置 //,行的其它部分将被解释器丢弃。另外,/* 和 */ 之间的任何内容也将被丢弃。
// 这是一个注释,会被解释器忽略
/* 这也被忽略 */
必要的库
库由两部分组成:
- 头文件,其中包含函数说明
- 包含函数定义的源文件
头文件包含在源文件中,而库文件的源文件则链接到可执行文件。因此,此示例所需的头文件是:
“`
// 输入/输出功能
include
// 标准库
include
// 字符串操作功能
include
// BSD 队列
include
// GSL 科学功能
include
include
“`
主函数
在 C 语言中,程序必须位于称为主函数 main() 的特殊函数内:
int main(void) {
...
}
这与上一教程中介绍的 Python 不同,后者将运行在源文件中找到的所有代码。
定义变量
在 C 语言中,变量必须在使用前声明,并且必须与类型关联。每当你要使用变量时,都必须决定要在其中存储哪种数据。你也可以指定是否打算将变量用作常量值,这不是必需的,但是编译器可以从此信息中受益。 以下来自存储库中的 fitting_C99.c 程序:
const char *input_file_name = "anscombe.csv";
const char *delimiter = "\t";
const unsigned int skip_header = 3;
const unsigned int column_x = 0;
const unsigned int column_y = 1;
const char *output_file_name = "fit_C99.csv";
const unsigned int N = 100;
C 语言中的数组不是动态的,从某种意义上说,数组的长度必须事先确定(即,在编译之前):
int data_array[1024];
由于你通常不知道文件中有多少个数据点,因此请使用单链列表。这是一个动态数据结构,可以无限增长。幸运的是,BSD 提供了链表。这是一个示例定义:
“`
struct data_point {
double x;
double y;
SLIST_ENTRY(data_point) entries;
};
SLISTHEAD(datalist, datapoint) head = SLISTHEADINITIALIZER(head);
SLISTINIT(&head);
“`
该示例定义了一个由结构化值组成的 data_point 列表,该结构化值同时包含 x 值和 y 值。语法相当复杂,但是很直观,详细描述它就会太冗长了。
打印输出
要在终端上打印,可以使用 printf() 函数,其功能类似于 Octave 的 printf() 函数(在第一篇文章中介绍):
printf("#### Anscombe's first set with C99 ####\n");
printf() 函数不会在打印字符串的末尾自动添加换行符,因此你必须添加换行符。第一个参数是一个字符串,可以包含传递给函数的其他参数的格式信息,例如:
printf("Slope: %f\n", slope);
读取数据
现在来到了困难的部分……有一些用 C 语言解析 CSV 文件的库,但是似乎没有一个库足够稳定或流行到可以放入到 Fedora 软件包存储库中。我没有为本教程添加依赖项,而是决定自己编写此部分。同样,讨论这些细节太啰嗦了,所以我只会解释大致的思路。为了简洁起见,将忽略源代码中的某些行,但是你可以在存储库中找到完整的示例代码。
首先,打开输入文件:
FILE* input_file = fopen(input_file_name, "r");
然后逐行读取文件,直到出现错误或文件结束:
“`
while (!ferror(inputfile) && !feof(inputfile)) {
sizet buffersize = 0;
char *buffer = NULL;
getline(&buffer, &buffer_size, input_file);
...
}
“`
getline() 函数是 POSIX.1-2008 标准新增的一个不错的函数。它可以读取文件中的整行,并负责分配必要的内存。然后使用 strtok() 函数将每一行分成 字元 。遍历字元,选择所需的列:
“`
char *token = strtok(buffer, delimiter);
while (token != NULL)
{
double value;
sscanf(token, “%lf”, &value);
if (column == column_x) {
x = value;
} else if (column == column_y) {
y = value;
}
column += 1;
token = strtok(NULL, delimiter);
}
“`
最后,当选择了 x 和 y 值时,将新数据点插入链表中:
“`
struct datapoint *datum = malloc(sizeof(struct datapoint));
datum->x = x;
datum->y = y;
SLISTINSERTHEAD(&head, datum, entries);
“`
malloc() 函数为新数据点动态分配(保留)一些持久性内存。
拟合数据
GSL 线性拟合函数 gslfitlinear() 期望其输入为简单数组。因此,由于你将不知道要创建的数组的大小,因此必须手动分配它们的内存:
“`
const sizet entriesnumber = row – skip_header – 1;
double *x = malloc(sizeof(double) * entriesnumber);
double *y = malloc(sizeof(double) * entriesnumber);
“`
然后,遍历链表以将相关数据保存到数组:
“`
SLISTFOREACH(datum, &head, entries) {
const double currentx = datum->x;
const double current_y = datum->y;
x[i] = current_x;
y[i] = current_y;
i += 1;
}
“`
现在你已经处理完了链表,请清理它。要总是释放已手动分配的内存,以防止内存泄漏。内存泄漏是糟糕的、糟糕的、糟糕的(重要的话说三遍)。每次内存没有释放时,花园侏儒都会找不到自己的头:
“`
while (!SLISTEMPTY(&head)) {
struct datapoint *datum = SLIST_FIRST(&head);
SLIST_REMOVE_HEAD(&head, entries);
free(datum);
}
“`
终于,终于!你可以拟合你的数据了:
“`
gslfitlinear(x, 1, y, 1, entriesnumber,
&intercept, &slope,
&cov00, &cov01, &cov11, &chisquared);
const double rvalue = gslstatscorrelation(x, 1, y, 1, entriesnumber);
printf(“Slope: %f\n”, slope);
printf(“Intercept: %f\n”, intercept);
printf(“Correlation coefficient: %f\n”, r_value);
“`
绘图
你必须使用外部程序进行绘图。因此,将拟合数据保存到外部文件:
“`
const double stepx = ((maxx + 1) – (min_x – 1)) / N;
for (unsigned int i = 0; i < N; i += 1) {
const double currentx = (minx – 1) + stepx * i;
const double currenty = intercept + slope * current_x;
fprintf(output_file, "%f\t%f\n", current_x, current_y);
}
“`
用于绘制两个文件的 Gnuplot 命令是:
plot 'fit_C99.csv' using 1:2 with lines title 'Fit', 'anscombe.csv' using 1:2 with points pointtype 7 title 'Data'
结果
在运行程序之前,你必须编译它:
clang -std=c99 -I/usr/include/ fitting_C99.c -L/usr/lib/ -L/usr/lib64/ -lgsl -lgslcblas -o fitting_C99
这个命令告诉编译器使用 C99 标准、读取 fitting_C99.c 文件、加载 gsl 和 gslcblas 库、并将结果保存到 fitting_C99。命令行上的结果输出为:
“`
Anscombe’s first set with C99
Slope: 0.500091
Intercept: 3.000091
Correlation coefficient: 0.816421
“`
这是用 Gnuplot 生成的结果图像:

C++11 方式
C++ 语言是一种通用编程语言,也是当今使用的最受欢迎的语言之一。它是作为 C 的继承人创建的(诞生于 1983 年),重点是面向对象程序设计(OOP)。C++ 通常被视为 C 的超集,因此 C 程序应该能够使用 C++ 编译器进行编译。这并非完全正确,因为在某些极端情况下它们的行为有所不同。 根据我的经验,C++ 与 C 相比需要更少的样板代码,但是如果要进行面向对象开发,语法会更困难。C++11 标准是最新版本,增加了一些漂亮的功能,并且基本上得到了编译器的支持。
由于 C++ 在很大程度上与 C 兼容,因此我将仅强调两者之间的区别。我在本部分中没有涵盖的任何部分,则意味着它与 C 中的相同。
安装
这个 C++ 示例的依赖项与 C 示例相同。 在 Fedora 上,运行:
sudo dnf install clang gnuplot gsl gsl-devel
必要的库
库的工作方式与 C 语言相同,但是 include 指令略有不同:
“`
include
include
include
include
include
include
include
extern “C” {
include
include
}
“`
由于 GSL 库是用 C 编写的,因此你必须将这个特殊情况告知编译器。
定义变量
与 C 语言相比,C++ 支持更多的数据类型(类),例如,与其 C 语言版本相比,string 类型具有更多的功能。相应地更新变量的定义:
const std::string input_file_name("anscombe.csv");
对于字符串之类的结构化对象,你可以定义变量而无需使用 = 符号。
打印输出
你可以使用 printf() 函数,但是 cout 对象更惯用。使用运算符 << 来指示要使用 cout 打印的字符串(或对象):
“`
std::cout << “#### Anscombe’s first set with C++11 ####” << std::endl;
…
std::cout << “Slope: ” << slope << std::endl;
std::cout << “Intercept: ” << intercept << std::endl;
std::cout << “Correlation coefficient: ” << r_value << std::endl;
“`
读取数据
该方案与以前相同。将打开文件并逐行读取文件,但语法不同:
“`
std::ifstream inputfile(inputfile_name);
while (input_file.good()) {
std::string line;
getline(input_file, line);
...
}
“`
使用与 C99 示例相同的功能提取行字元。代替使用标准的 C 数组,而是使用两个向量。向量是 C++ 标准库中对 C 数组的扩展,它允许动态管理内存而无需显式调用 malloc():
“`
std::vector
std::vector
// Adding an element to x and y:
x.emplaceback(value);
y.emplaceback(value);
“`
拟合数据
要在 C++ 中拟合,你不必遍历列表,因为向量可以保证具有连续的内存。你可以将向量缓冲区的指针直接传递给拟合函数:
“`
gslfitlinear(x.data(), 1, y.data(), 1, entriesnumber,
&intercept, &slope,
&cov00, &cov01, &cov11, &chisquared);
const double rvalue = gslstatscorrelation(x.data(), 1, y.data(), 1, entriesnumber);
std::cout << “Slope: ” << slope << std::endl;
std::cout << “Intercept: ” << intercept << std::endl;
std::cout << “Correlation coefficient: ” << r_value << std::endl;
“`
绘图
使用与以前相同的方法进行绘图。 写入文件:
“`
const double stepx = ((maxx + 1) – (min_x – 1)) / N;
for (unsigned int i = 0; i < N; i += 1) {
const double currentx = (minx – 1) + stepx * i;
const double currenty = intercept + slope * current_x;
output_file << current_x << "\t" << current_y << std::endl;
}
output_file.close();
“`
然后使用 Gnuplot 进行绘图。
结果
在运行程序之前,必须使用类似的命令对其进行编译:
clang++ -std=c++11 -I/usr/include/ fitting_Cpp11.cpp -L/usr/lib/ -L/usr/lib64/ -lgsl -lgslcblas -o fitting_Cpp11
命令行上的结果输出为:
“`
Anscombe’s first set with C++11
Slope: 0.500091
Intercept: 3.00009
Correlation coefficient: 0.816421
“`
这就是用 Gnuplot 生成的结果图像:

结论
本文提供了用 C99 和 C++11 编写的数据拟合和绘图任务的示例。由于 C++ 在很大程度上与 C 兼容,因此本文利用了它们的相似性来编写了第二个示例。在某些方面,C++ 更易于使用,因为它部分减轻了显式管理内存的负担。但是其语法更加复杂,因为它引入了为 OOP 编写类的可能性。但是,仍然可以用 C 使用 OOP 方法编写软件。由于 OOP 是一种编程风格,因此可以在任何语言中使用。在 C 中有一些很好的 OOP 示例,例如 GObject 和 Jansson库。
对于数字运算,我更喜欢在 C99 中进行,因为它的语法更简单并且得到了广泛的支持。直到最近,C++11 还没有得到广泛的支持,我倾向于避免使用先前版本中的粗糙不足之处。对于更复杂的软件,C++ 可能是一个不错的选择。
你是否也将 C 或 C++ 用于数据科学?在评论中分享你的经验。
via: https://opensource.com/article/20/2/c-data-science
作者:Cristiano L. Fontana 选题:lujun9972 译者:wxy 校对:wxy
主题测试文章,只做测试使用。发布者:eason,转转请注明出处:https://aicodev.cn/2020/03/02/%e5%9c%a8%e6%95%b0%e6%8d%ae%e7%a7%91%e5%ad%a6%e4%b8%ad%e4%bd%bf%e7%94%a8-c-%e5%92%8c-c/